February 15, 2026
The OSEMN Framework: The 5-Step Process Behind Every Successful Data Science Project
Most data science projects fail.
Not because of bad algorithms. Not because of bad data. But because teams have no repeatable process for going from raw data to real business outcomes.
That’s where the OSEMN framework comes in.
OSEMN (pronounced “awesome”) is a 5-step framework that gives you a clear, battle-tested roadmap for every data science project — from data collection all the way to actionable insights.
In this post, I’ll break down each step, show you exactly how it works, and explain why top data teams swear by it.
Let’s dive in.
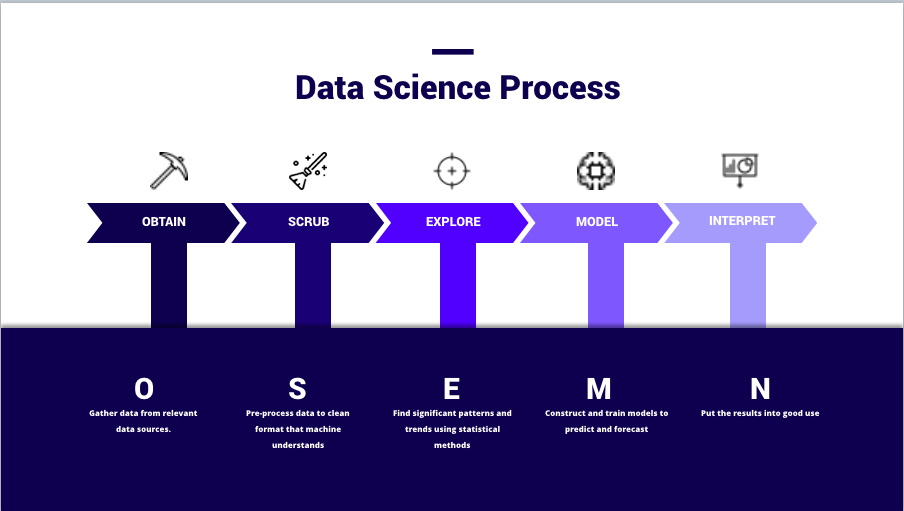
What Is the OSEMN Framework?
OSEMN was first introduced by Hilary Mason and Chris Wiggins. It stands for:
- O — Obtain
- S — Scrub
- E — Explore
- M — Model
- N — iNterpret
Think of it as a checklist for your data science workflow.
Each step builds on the one before it. Skip a step (or rush through it), and the whole project falls apart downstream.
Here’s the thing:
Most beginners jump straight to the “Model” step. They want to build a neural network on day one. But modelling is only step 4 out of 5.
The best data scientists spend 80% of their time on steps 1 through 3.
Let me show you why.
Step 1: Obtain
This is where everything starts.
You need data. And you need to figure out where to get it.
That sounds simple. It’s not.
In fact, obtaining the right data is one of the most underrated skills in data science. Because the quality of your final output is directly tied to the quality of what goes in.
Here’s what “Obtain” looks like in practice:
- Pulling data from APIs (Twitter, Google Analytics, internal systems)
- Querying databases (SQL, NoSQL, data warehouses)
- Scraping data from the web
- Importing CSV files, spreadsheets, or JSON from partners or clients
- Connecting to real-time data streams (IoT sensors, event logs)
The key question at this stage: “Do I have the data I need to answer the business question?”
If the answer is no, stop. Go find it. Because no amount of fancy modelling will save a project built on incomplete data.
Step 2: Scrub
Here’s the deal:
Real-world data is messy. Really messy.
Missing values. Duplicate rows. Inconsistent formats. Typos in category labels. Dates stored as strings. You name it.
That’s why step 2 exists.
“Scrubbing” means cleaning and preprocessing your data until it’s ready for analysis. This is the step that nobody talks about at conferences — but it’s where projects are won or lost.
Common scrubbing tasks include:
- Handling missing values (imputation, removal, or flagging)
- Removing duplicates
- Standardising formats (dates, currencies, units)
- Fixing data types (converting strings to numbers, parsing timestamps)
- Dealing with outliers that could skew your results
- Encoding categorical variables for model consumption
Here’s a stat that surprises people:
Data scientists typically spend 50–80% of their project time on this step alone.
It’s tedious. It’s unglamorous. And it’s absolutely critical.
Garbage in, garbage out. That’s not just a saying — it’s the number one reason data projects fail.
Step 3: Explore
Now it gets interesting.
Exploration is where you start to actually understand your data. You’re looking for patterns, anomalies, relationships, and surprises.
This is the step where intuition meets analysis.
Your toolkit here:
- Summary statistics (mean, median, standard deviation, distributions)
- Data visualisation (histograms, scatter plots, heatmaps, box plots)
- Correlation analysis (which features move together?)
- Segmentation (are there natural groupings in the data?)
- Hypothesis generation (what could explain what you’re seeing?)
And the best part?
This step often reveals insights that are valuable on their own — before you even build a model.
I’ve had projects where a well-crafted exploratory chart answered the client’s question entirely. No machine learning needed.
Pro tip: Don’t skip this step. Even if you’re under pressure to “just build the model.” Exploration prevents you from building the wrong model.
Step 4: Model
This is the step everyone wants to jump to.
Modelling is where you apply algorithms to your data to make predictions, classify outcomes, or uncover hidden structure.
But here’s what most people miss:
The best model is the simplest model that solves the problem.
You don’t always need deep learning. Sometimes a logistic regression or a decision tree gets you 90% of the way there — and it’s interpretable, fast, and cheap to deploy.
The modelling process typically looks like this:
- Choose your approach — Supervised? Unsupervised? Regression? Classification?
- Select candidate algorithms — Start simple, then increase complexity if needed
- Split your data — Training, validation, and test sets
- Train and tune — Hyperparameter optimisation, cross-validation
- Evaluate performance — Accuracy, precision, recall, F1, RMSE — pick the metric that matters for your use case
One more thing:
Try multiple models. Don’t marry the first algorithm you test. Compare at least 2–3 approaches before deciding.
Step 5: iNterpret
This is where data science becomes business science.
You’ve got results. Now what?
Interpretation is the step that separates data scientists from data reporters. It’s where you translate model outputs into decisions, actions, and strategy.
Questions to ask at this stage:
- What do the results mean in plain language?
- Are the results trustworthy? (Check for overfitting, bias, data leakage)
- What should the business do differently based on these findings?
- What are the limitations of this analysis?
- How do we communicate this to non-technical stakeholders?
Here’s the reality:
A model that’s 95% accurate but can’t be explained to the CEO is worth less than a model that’s 85% accurate and drives a clear business decision.
Interpretation is where value is created. Everything before it is preparation.
Why OSEMN Works
So why does this 5-step framework work so well?
Three reasons:
1. It’s sequential but iterative. You follow the steps in order, but you can (and should) loop back. Your exploration might reveal that you need more data. Your modelling results might send you back to scrubbing. That’s normal.
2. It prevents the biggest mistakes. Most failed data projects skip the “boring” early steps. OSEMN forces you to do the unglamorous work that actually matters.
3. It’s universal. Whether you’re building a recommendation engine, predicting customer churn, or analysing medical data — the OSEMN process applies.
Bottom Line
The OSEMN framework isn’t complicated. That’s the point.
It gives data science teams a shared language and a repeatable process. And in a field where projects fail more often than they succeed, having a proven playbook is everything.
Here’s my suggestion:
Print out the 5 steps. Pin them next to your monitor. Before you start your next project, walk through each one. You’ll catch problems earlier, build better models, and — most importantly — deliver results that actually move the needle.
Obtain. Scrub. Explore. Model. iNterpret.
That’s OSEMN. And yes — it really is awesome.